Analyzing Metadata from Spotify Playlists
I recently came across this post about a Python module GSA that allows you to download metadata from Spotify playlists.1 This was great, because it was a perfect opportunity for me to test RStudio 1.4’s improved support for Python, which I had been excited to try out since I saw the news.
Download Metadata
The original blog post lays out the steps you need to install everything properly, so I won’t repeat them here. However, I’ll briefly go over a few problems I encountered while trying to get it to work in the context of RStudio.
The blog post tells you to run
pip install -r requirements.txtto install the necessary packages for their GSA module. If you are usingreticulatein R/RStudio 1.4, you may also need to install those packages withpy_installso that those packages are installing to the environment used by reticulate.In order for
import GSAto work, Python has to be able to findGSA.py(and the other python scripts) in either the current working directory or some other directory that Python knows to search in. You can check what the current working directory is withos.getcwd(). If it is not there, then you can add the directory containingGSA.pyto the path withsys.path.insert. For example, in my case, when I downloaded the Python scripts, I had them in a subdirectory of my project folder, so I had to add that subdirectory, “GeneralizedSpotifyAnalyser-main,” to my Python path:
| |
After successfully importing GSA, I followed the sample script GSA_basicExample.py to download the playlist metadata. The playlist I’m using as an example is “Chillin’ on a Dirt Road.”
| |
I also modified the GSA.getInformation function slightly to add an additional column for artist names. If you poke around the track variable in the function, you may also find other metadata fields that you are interested in, since the function by default doesn’t save all of the fields into the data frame. The artists are under track['track']['artists'] and their names can be accessed in Python as [x['name'] for x in track['track']['artists']].
Regarding RStudio 1.4’s integration with Python, I did have quite a smooth experience running everything. I could send lines of Python code to the RStudio console just like R code. I also noticed that RStudio will automatically detect whether you are trying to run Python or R code and enter and exit reticulate for you. In addition, Python variables show up in the Environment tab of RStudio, which isn’t something I personally use a lot, but it’s still cool to see. Based on this limited experience, RStudio seems to be able to function like an IDE for Python.
Some of these features may have already existed pre-RStudio 1.4, because I will say that the last time I used reticulate, I remember having a rather good experience already. For example, something really cool about reticulate is that you can switch from Python back to R and access any Python object with py$name_of_object. I don’t know how this extraordinary magic is implemented, but it’s amazing.
|
|
Below I’ve print out the data frame in R, which was originally downloaded in Python.
|
|
|
|
Plot the Data
Once I have the data, I can make all sorts of interesting plots. First, I clean up the data a bit using the R packages janitor (for column names) and lubridate (for dates).
| |
Then I use ggplot2 to make some fun visualizations of the songs in the playlist.
| |
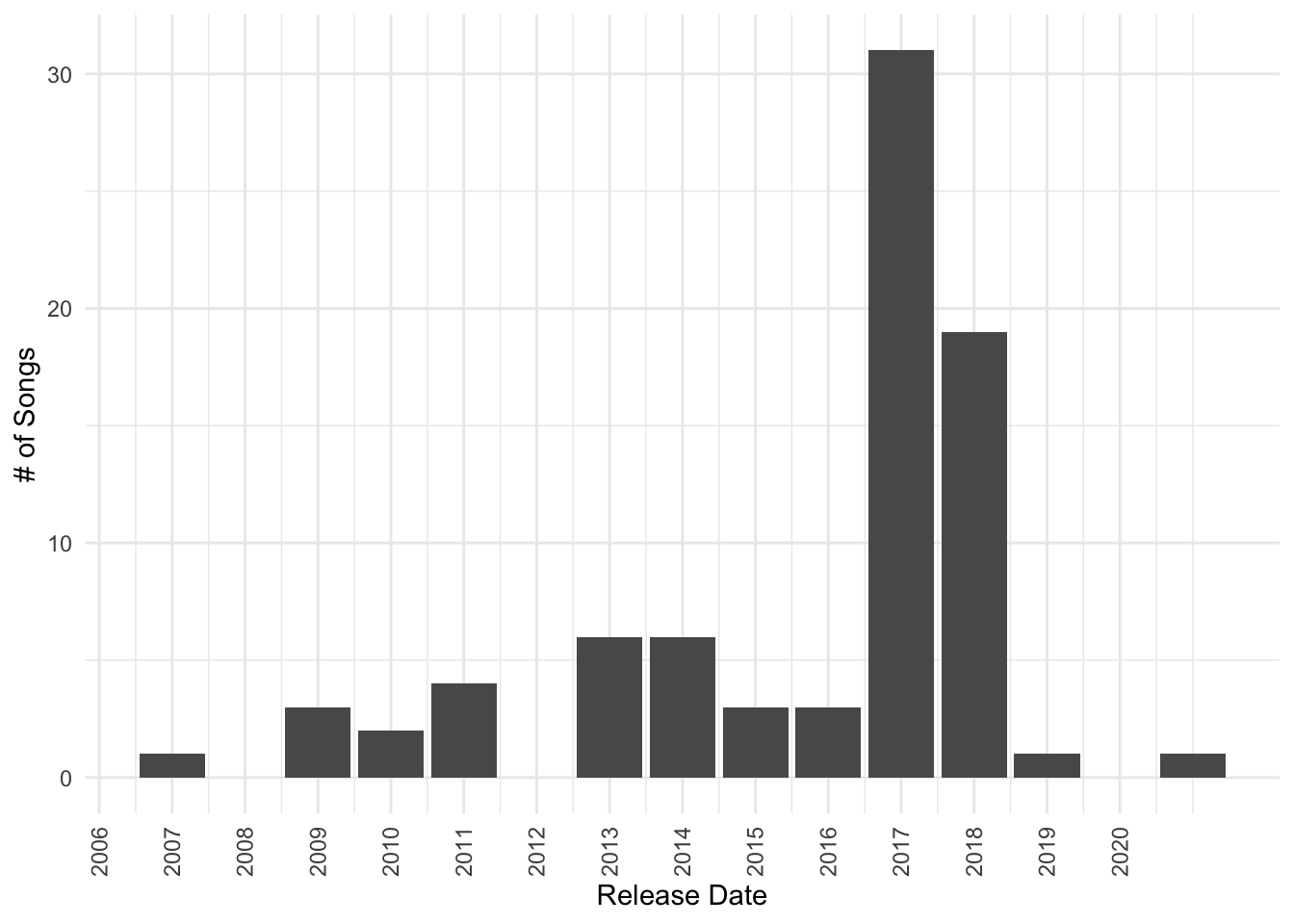
| |
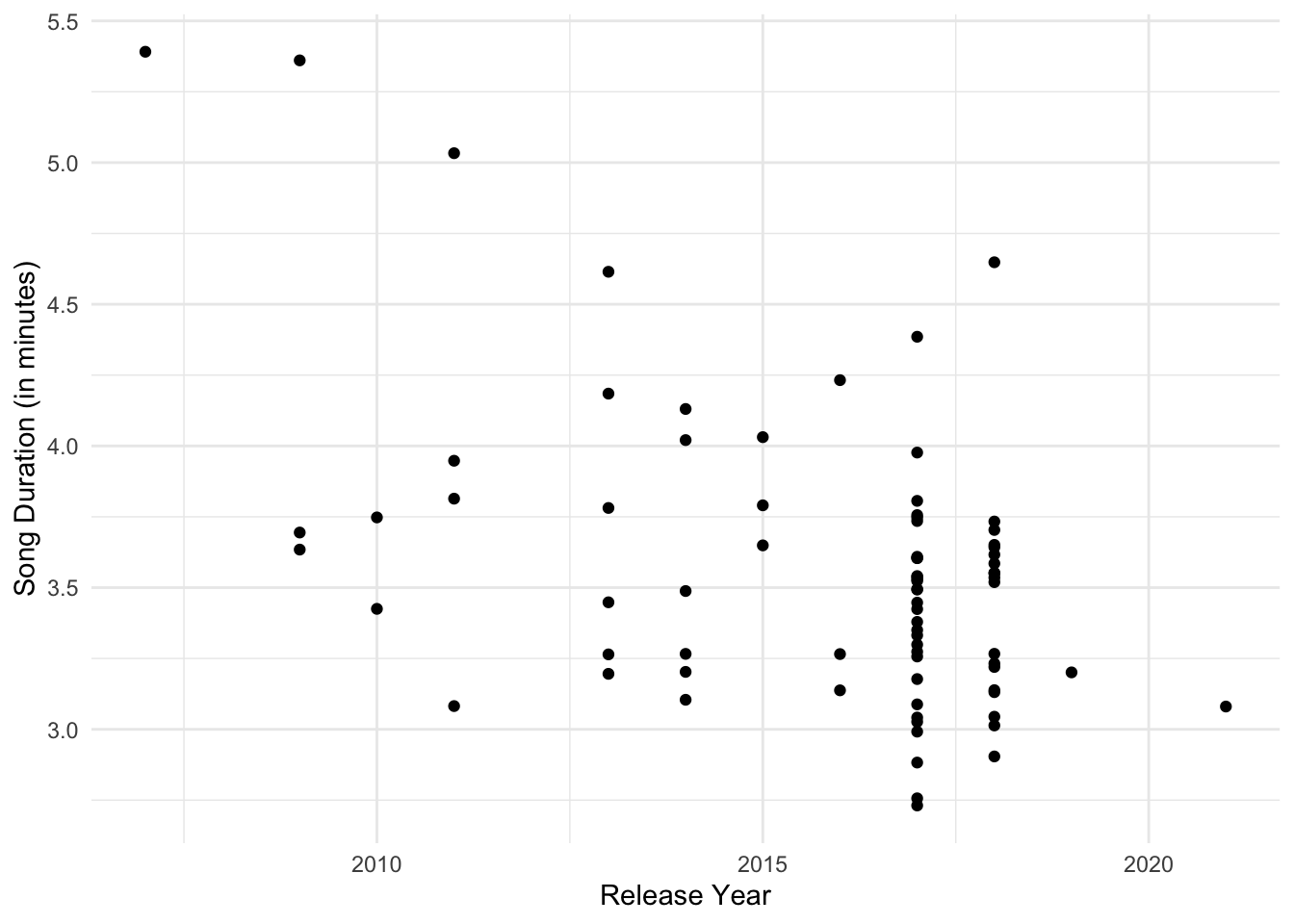
| |
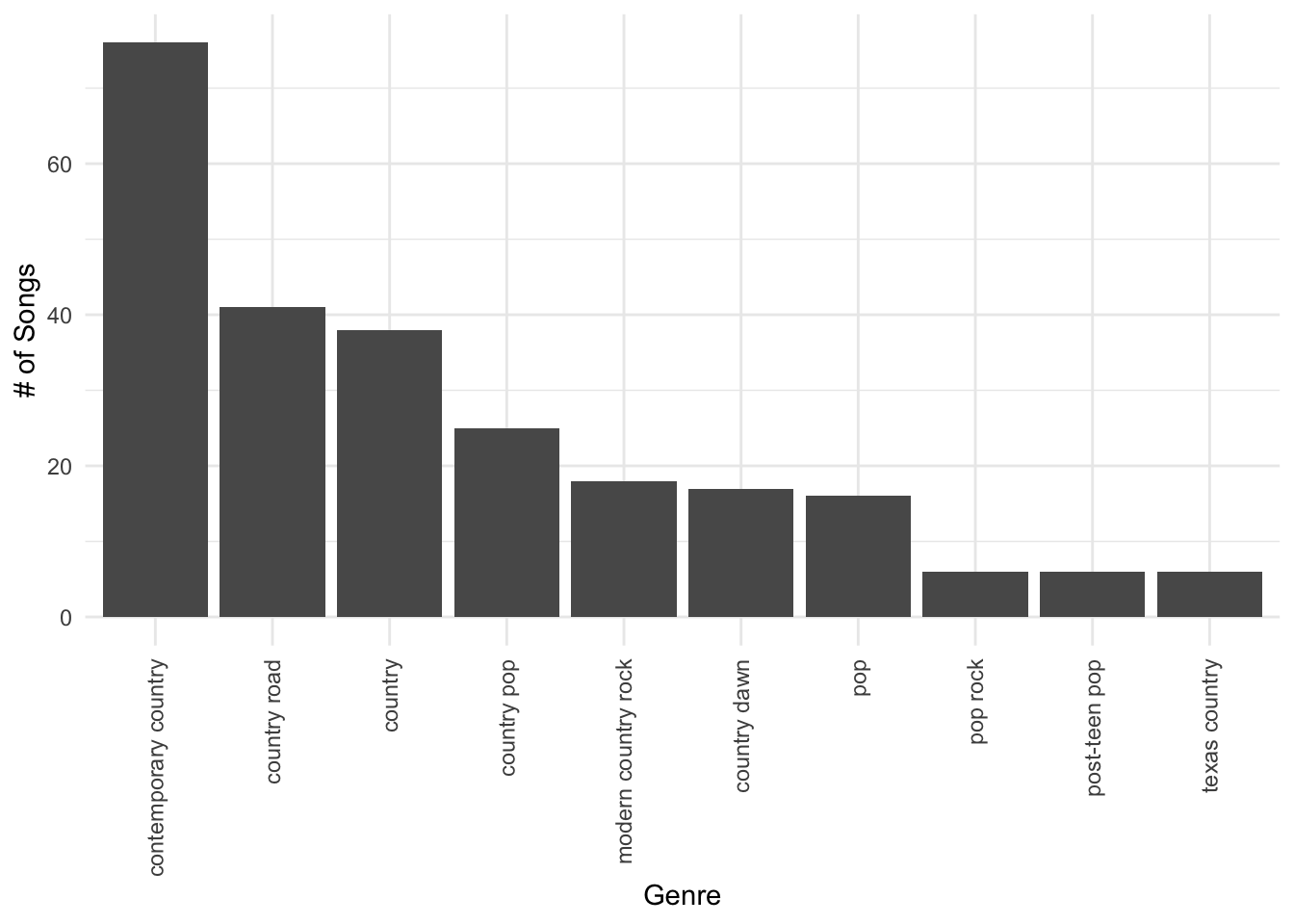
After I wrote this post, I discovered that an R package for Spotify has since been released, which I expect will be easier to use for R users.↩︎