Treating Data with Caution
I recently came across some interesting stories about data that I thought were good examples of how data can be misleading.
The first story is this thread on X (Twitter), in which Ben Schmidt critiques a recent tweet/Financial Times article from John Burn-Murdoch.1 John cites and extends analysis from an economics paper that argues that books have begun talking less about “progress and future” and more about “caution, worry, and risk” over the last 60 years based on data from the Google Ngram project.
But as Ben points out, the corpus of books that falls under the scope of the Google Ngram project changes over time. In particular, in the 1970s and 80s, the amount of fiction in the corpus probably increased significantly. This means that comparisons about the frequency of words and phrases across time with the dataset are unlikely to be an apples-to-apples comparison and it is likely why you see significant trend breaks in those decades.2
Another story I came across recently is this one by Noah Smith about rising maternal mortality in the U.S. Noah discusses a plot by the Commonwealth Fund in 2022 that suggests maternal mortality in the U.S. far exceeded that of other countries in recent years. However, he then points out that the elevated maternal mortality in the U.S. may actually be illusory in part. This is because according to Joseph et al. (2021), the death certificate was revised in 2003 to include a pregnancy checkbox and states made this revision in a staggered manner, which led to an increase in the identification of maternal deaths in the subsequent years.
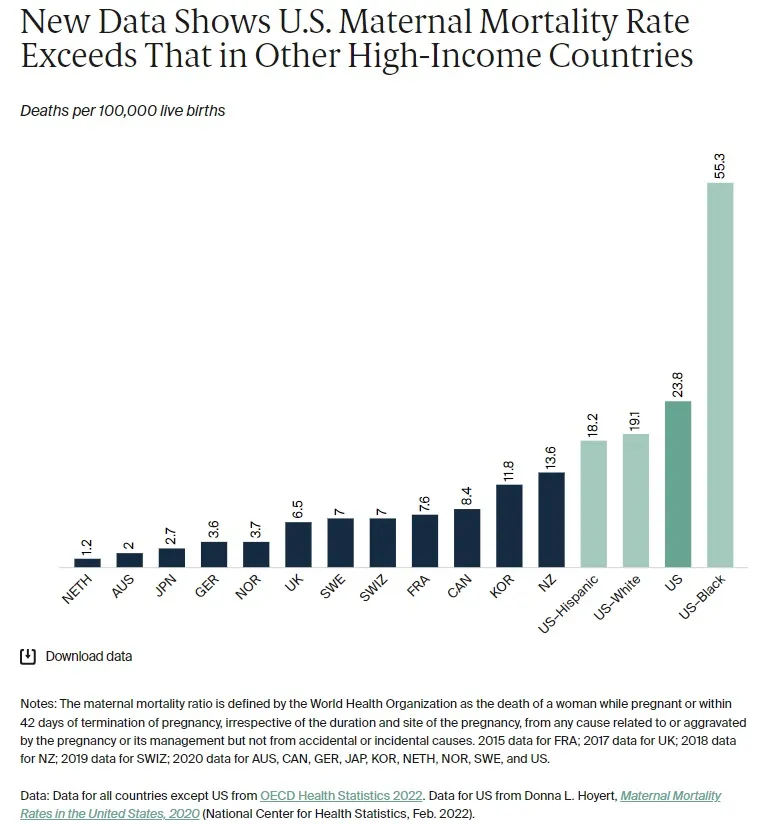
Data artifacts like these are subtle and not easy to spot, especially for people who aren’t familiar with the field or the data. I certainly wouldn’t have thought to question these findings myself to begin with. I think this goes to show why domain expertise and understanding your data are so important. Otherwise, it’s easy to draw wrong conclusions from your data.
I think this is also why I’m rather skeptical whenever people suggest AI is going to solve everything. Currently, models aren’t able to independently fix such data artifacts because they take their ingested data as fact, so you still need humans to point out these artifacts to begin with.
Incidentally, John Burn-Murdoch creates some wonderful data visualizations and I really like his work, notwithstanding this story.↩︎
He expands on this idea more in a 2021 thread critiquing another research article that was also based on the Google Books corpus.↩︎